
Il ne fait aucun doute que l'analyse prédictive fait fureur ces dernières années - et pour cause. La nouvelle discipline basée sur des algorithmes nous a permis d'apporter des informations qui fournissent des détails sur la probabilité d'un résultat donné, ainsi que de nous aider à obtenir celles qui sont favorables.
Les cas d'utilisation de la science des données et de la modélisation prédictive se présentent sous la forme d'outils de planification de voyage, où les clients peuvent définir les lieux, les dates, les adhésions au programme de miles, les besoins de l'hôtel et d'autres facteurs qui affectent les détails du voyage. Ces produits marquent une évolution vers une science des données conviviale, avec des outils qui transforment essentiellement le client en data scientist, leur permettant de créer leurs propres modèles pour retourner les résultats souhaités.
Nous avons même vu la science des données et la modélisation prédictive utilisées par des entreprises influentes comme Airbnb.
En 2014, les hôtes Airbnb ont eu un problème: ils n'ont jamais su tarifer leurs locations. Il y avait tellement de variables: la saisonnalité, l'emplacement et les préférences individuelles, ainsi que les commodités et les caractéristiques uniques de chaque propriété. Comment les hôtes pouvaient-ils proposer des frais de nuit à la fois reflétant tous ces facteurs et susceptibles de leur procurer une réservation?
Airbnb utilise la science des données pour résoudre de nombreux problèmes à l'échelle de l'entreprise; auparavant, ils s'appuyaient sur des informations basées sur des données pour améliorer la diversité des sexes de leur équipe. Ainsi, lorsque les hôtes avaient besoin d'aide pour choisir leurs prix, il était logique de créer une sélection de modèles prédictifs pour eux.
Entrez dans le modèle Aerosolve , un modèle de tarification dynamique conçu pour synthétiser plusieurs variables afin d'aider les listeurs à choisir le tarif idéal pour leur location. Cet outil est cependant plus qu'un simple algorithme. Il utilise la technologie d'apprentissage automatique pour que les données soient réinjectées en continu dans l'outil. Réalisant que Aerosolve avait de nombreuses applications potentielles supplémentaires, Airbnb a décidé de télécharger le code sur Github pour un accès open source.
Cependant, ce qui est unique dans le modèle, c'est sa convivialité. Les couches sont compressées dans un format simplifié qui permet aux utilisateurs finaux de comprendre les informations — dans ce cas, leur probabilité de recevoir une réservation — lorsqu'ils ajustent des facteurs tels que le prix et la date.
La présentation d'outils prédictifs dans une interface utilisateur facile à digérer et orientée consommateur est exactement ce que l'avenir réserve à la science des données.

De prédictif à prescriptif
Ces applications sont également emblématiques d'un changement qui traverse la science des données commerciales. Les scientifiques des données s'orientent vers des applications pratiques de la modélisation prescriptive plutôt que prédictive. Alors que ce dernier utilise des données historiques pour prédire la probabilité d'avenir des événements (c'est-à-dire la probabilité qu'il pleuve demain), le premier suppose un agent humain actif capable d'influencer les résultats.
Définitions rapides :
- L'analyse descriptive est la première étape de l'analyse commerciale dans laquelle vous examinez les données historiques et les performances.
- L'analyse prédictive est la deuxième étape de l'analyse commerciale dans laquelle les données passées sont utilisées avec des algorithmes pour prédire un résultat futur.
- L'analyse normative est la troisième étape de l'analyse commerciale dans laquelle vous déterminez le meilleur plan d'action.
Les scientifiques des données peuvent construire un modèle de rehaussement normatif pour prédire la probabilité de convertir un prospect avec une certaine offre, par exemple, ou pour dire si l'offre d'une prime de connexion influencera la probabilité qu'un employé potentiel accepte le poste.
De cette façon, il est beaucoup plus utile pour une planification proactive, comme dans le cas d'utilisation d'Airbnb. Il marque également un flou de la frontière entre la machine et les interactions humaines. Les modèles prédictifs plus anciens, par exemple, offraient simplement aux utilisateurs finaux un aperçu de la probabilité d'un événement. Il appartenait aux agents humains de décider quoi faire de ces informations.
La modélisation prescriptive de l'élévation, cependant, peut calculer les résultats d'un événement si les utilisateurs finaux choisissent de suivre un certain plan d'action. Il peut donc estimer si une campagne marketing est susceptible de gagner un certain groupe démographique ou proposer des solutions pour une campagne politique dans l'espoir de séduire les électeurs swing.
Les applications potentielles de ce type de données proactives sont pratiquement innombrables; il est particulièrement utile pour prédire les résultats dans le commerce de détail, les ventes, le marketing, la politique et les dons de bienfaisance, essentiellement partout où les utilisateurs espèrent inspirer les populations vers un certain comportement.
Lectures complémentaires:
- Comment utiliser l'analyse prédictive pour de meilleures performances marketing
- Le parcours de l'acheteur 101: ce que vos données de messagerie électronique disent à propos de vos clients
- Comment écrire du contenu pour les gens et l'optimiser pour Google
Deep Learning: les machines adoptent les schémas de traitement de leurs créateurs
La tendance à la modélisation normative est un développement intéressant, philosophiquement parlant, étant donné la popularité croissante des technologies d'apprentissage automatique. Les scientifiques des données modernes sont souvent appelés à travailler en étroite collaboration avec les ingénieurs logiciels dans le développement de nouveaux outils automatisés, et bon nombre de ces produits utiliseront la technologie d'apprentissage automatique.
Vous avez probablement déjà entendu parler de cette évolution technologique - c'est un mot à la mode très populaire dans le domaine de la science des données en ce moment. Cependant, ce qui est moins bien connu, c'est précisément ce qu'est l'apprentissage automatique et comment il se rapporte au Big Data et à la science des données.
L'apprentissage automatique offre des applications extraordinairement puissantes de big data et de probabilité statistique. Il brise les divisions entre la collecte et le traitement des données.
Ici, les machines ajustent progressivement le comportement et les réponses en fonction des données environnementales; d'où la partie «apprentissage» du nom. Un exemple concret de cela est l'outil de recommandation d'Amazon. Plus les utilisateurs alimentent l'outil en navigation et en achat, plus les recommandations deviennent précises.
De tels outils témoignent des interactions en temps réel entre les humains et les appareils. Alors que les humains répondent aux résultats, les machines adaptent leurs prochaines offres en fonction de ces commentaires. Cela ressemble beaucoup plus à une conversation qu'à une chaîne de commandes.
Un segment particulier de l'apprentissage automatique, connu sous le nom d'apprentissage en profondeur, pousse cette évolution à l'extrême. L'apprentissage en profondeur modélise la structure et les schémas de traitement de l'esprit humain: les ordinateurs d'apprentissage en profondeur sont construits avec des réseaux de neurones, avec des couches de nœuds superposées. Cette architecture permet aux nœuds de se connecter entre eux de manière non linéaire, en faisant appel à certains domaines de traitement si nécessaire.
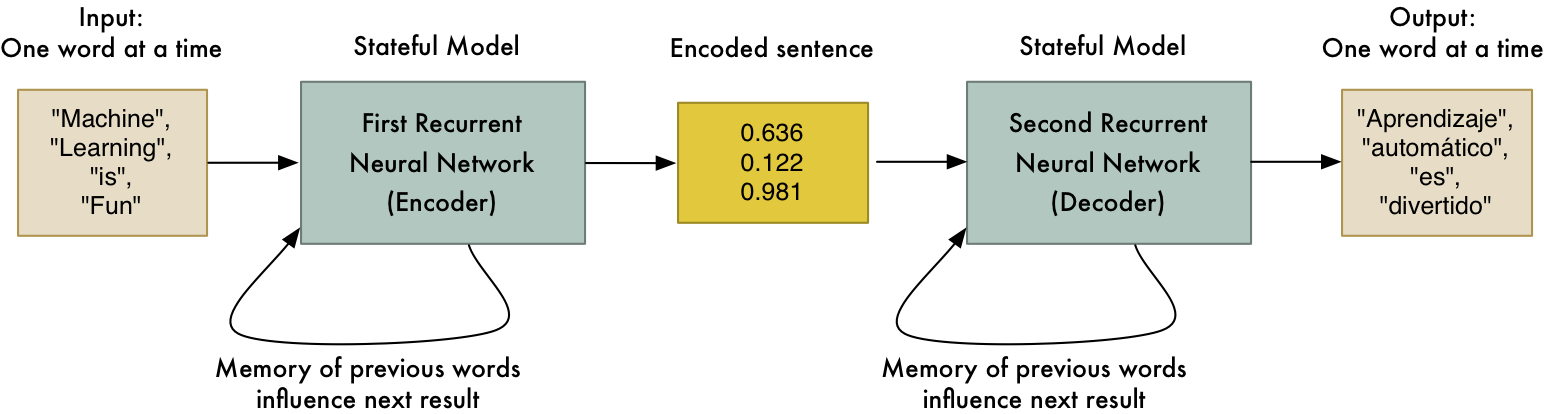
Les technologies d'apprentissage en profondeur sont particulièrement utiles pour imiter le type de traitement visuel effectué par le cerveau lorsqu'il réagit aux signaux des yeux.
Par exemple, l'application Google Translate utilise l'apprentissage en profondeur pour traduire le texte non incorporé d'images dans une autre langue. Un utilisateur voyageant dans un autre pays peut prendre une photo d'une boîte de céréales ou d'un panneau de signalisation et la télécharger sur Google Translate. Google identifie ensuite le texte sur la boîte et renvoie une traduction dans leur langue maternelle.
De même, un autre projet Google, Google Sunroof , prend des images de l'application Google Earth et crée des modèles 3D réalistes de toits à utiliser dans l'installation solaire. À l'aide de réseaux neuronaux d'apprentissage en profondeur, l'outil Toit ouvrant est capable de différencier les surfaces de toit des arbres ou des voitures, même avec l'existence de facteurs d'obscurcissement, comme l'ombre et la couverture des arbres.
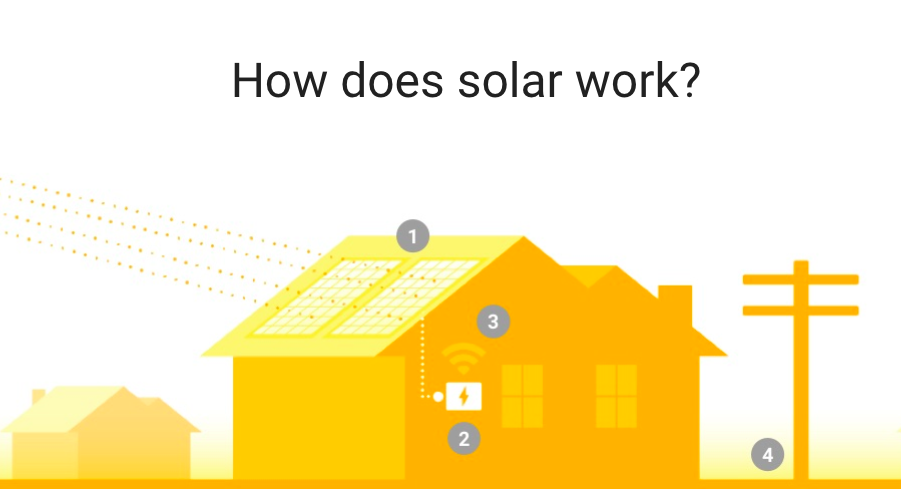
Des outils d'apprentissage en profondeur comme ceux-ci permettent aux scientifiques des données de construire des modèles prédictifs basés sur des données non structurées, telles que des images, de la vidéo et de l'audio, plutôt que de simplement s'appuyer sur des informations structurées comme du texte ou des chiffres. De cette façon, il ouvre d'énormes quantités de données commerciales qui n'avaient pas été exploitées auparavant.
Contenu connexe:
- 11 tendances du marketing numérique que vous ne pouvez plus ignorer en 2018
- Comment utiliser le Big Data Analytics pour augmenter votre retour sur investissement marketing
- L'avenir du référencement: comment l'IA et l'apprentissage automatique auront un impact sur le contenu
La science des données converge avec l'IA
L'apprentissage automatique et l'apprentissage en profondeur sont des applications de l'intelligence artificielle (IA), et l'utilisation croissante de technologies de l'IA comme celles-ci aura un impact profond sur la pratique de la science des données. Encore une fois, la tendance générale est l'évolution des outils qui sont simplement informatifs vers ceux qui sont transformationnels , comme l'a souligné à juste titre l'auteur et expert en intelligence artificielle Carlos Perez .
Les outils d'IA font le voyage de la collecte de données au traitement des données, et vont plus loin, en synthétisant les données dans des conceptions et des solutions.
Par exemple, le Project Dreamcatcher d'Autodesk est un système de conception assistée par ordinateur (CAO) qui utilise l'IA pour générer des conceptions de produits 3D en fonction de critères imputés par les concepteurs, tels que les objectifs fonctionnels, les matériaux requis, la méthode de fabrication et le budget.

La différence entre ce projet et le type d'outils en rotation régulière aujourd'hui est qu'ils ne permettent pas seulement aux utilisateurs finaux de créer des conceptions. Ils fournissent en fait des ensembles de solutions basées sur des données et aident les concepteurs à former des prototypes conçus pour résoudre des problèmes spécifiques.
Des outils comme ceux-ci anticipent un avenir où la science des données passera d'une fonction strictement analytique (synthétisant le Big Data et offrant des informations et des recommandations) à davantage d'applications de développement de produits et de R&D.
Cependant, certains experts pensent que les technologies de l'IA finiront par devenir si courantes qu'elles seront omniprésentes, inaugurant essentiellement une nouvelle révolution industrielle. Les appareils d'IA d'apprentissage automatique affecteront probablement un large éventail d'industries, de la publicité à la zoologie et tout le reste.
Les outils d'IA peuvent non seulement faire le travail de l'esprit humain, mais dans de nombreux cas, ils peuvent le faire plus efficacement que jamais. Des machines comme celles-ci sont capables de prouver mathématiquement des idées que les humains ne pouvaient que ressentir. Prenez, par exemple, la société Affectiva , qui utilise des équipements d'IA pour reconnaître les émotions humaines - colère, joie, surprise - aussi efficacement que les leaders humains des groupes de discussion commerciaux.
Lectures complémentaires:
- Comment l'intelligence artificielle révolutionne la sphère du marketing numérique
- Comment x.ai est venu avec l'idée d'Amy the Personal AI Assistant [podcast]
- Recherche vocale et IA: Amazon Alexa est-elle le début d'un empire robotique?
La fin de la science des données pilotée par l'homme?
Le succès des outils d'apprentissage automatique automatisés comme ceux décrits jusqu'à présent a laissé certains dans le domaine de la science des données se demander s'il arrivera un moment où les experts humains ne seront pas du tout nécessaires. Le potentiel de traitement avancé des réseaux de neurones peut très bien automatiser le travail des scientifiques des données - en substance, selon certains experts, les scientifiques des données peuvent très bien se retirer d'un travail.
La question se profile devant les employeurs d'aujourd'hui. Les scientifiques des données ont peut-être été surnommés «le travail le plus sexy du 21e siècle» en 2012 , mais aujourd'hui, l'avenir du rôle n'est pas aussi clair. Lors d'un récent symposium du MIT, les experts ont réfléchi à la durabilité du domaine, le vice-président de l'ADP et chef de la sécurité, Roland Cloutier, déclarant finalement qu'il n'était pas sage pour les étudiants en STEM en herbe de poursuivre la science des données, car, selon ses mots, «au fil du temps, les logiciels fera de plus en plus ce que les scientifiques des données font aujourd'hui. "
Comme le souligne Fortune , des outils comme Tableau ont déjà fait des progrès incroyables pour simplifier la visualisation des données, et de nombreux nouveaux programmes sont en cours de développement pour gérer les flux de travail et les interprétations des données.
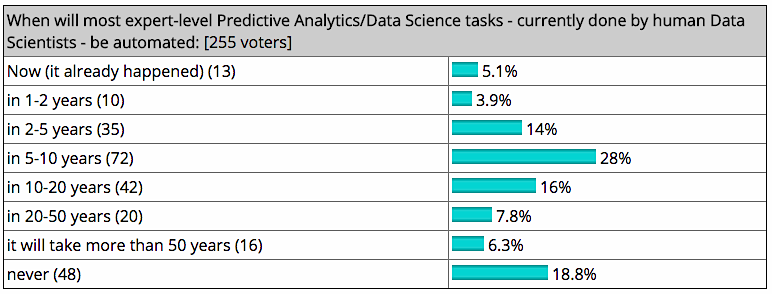
KDNuggets , un site de l'industrie pour les analystes commerciaux, les scientifiques des données et les développeurs d'apprentissage automatique, a récemment interrogé les lecteurs pour leur opinion sur la question. Seulement 18,8% estimaient que les scientifiques des données étaient irremplaçables par les machines. Cinquante et un pour cent, quant à eux, ont déclaré qu'ils s'attendaient à ce que la plupart des tâches soient automatisées en moins de 10 ans.
Bien sûr, tout le monde n'a pas une vision aussi sombre de la question. Comme le souligne la Harvard Business Review , les machines deviennent beaucoup plus «intelligentes», peut-être même plus que les humains dans certains cas. Et pourtant, ils manquent encore largement des capacités humaines pour raconter leur expérience. Les données et les informations peuvent être plus complexes, mais les appareils ne peuvent pas toujours nous dire comment ils y sont arrivés. Les machines peuvent être excellentes pour répondre aux questions, mais elles peuvent ne jamais être aussi compétentes que des experts humains pour trouver de nouveaux défis et problèmes à résoudre.
De même, il y a des moments où la précision surhumaine d'une machine la propulse à travers les frontières des mœurs sociales. Un exemple célèbre est la cible , qui a utilisé avec succès des données de consommation de prédire quand les clientes attendaient. Cela a créé la situation assez gênante d'un père apprenant la grossesse de sa fille adolescente à partir des annonces qu'elle a reçues par la poste. Ainsi, alors que les machines sont capables de faire des déductions complexes sur la base d'un comportement structuré, elles ne sont pas toujours en mesure de proposer une réponse sophistiquée et délicate, en particulier lorsque la réponse en question tombe dans une zone grise morale.
Cet argument pointe vers un avenir où les scientifiques des données se comporteront comme des «chuchoteurs», aidant les appareils à éviter les faux pas sociaux et générant les missions et les projets dans lesquels ils s'engagent.
Le futur proche de la science des données
Bien sûr, avec la technologie évoluant aussi vite qu'elle est, il est très difficile de prédire à quoi ressemblera n'importe quel travail dans 15 ans. En attendant, nous savons que la demande pour la science des données est en augmentation - IBM prévoit une augmentation de 28% d'ici 2020 - la majeure partie de cette croissance étant centrée sur la finance, l'assurance, les services professionnels et l'informatique.
Pour ceux qui travaillent dans la science des données, le défi sera de rester en avance sur la technologie. Les scientifiques des données doivent nager constamment, apprendre de nouveaux programmes et rester au courant de la direction du terrain. Cependant, étant donné que de nombreuses tâches pourraient devenir automatisées dans un avenir proche, il serait judicieux pour les entreprises créant ces emplois de rechercher des candidats qui pourraient éventuellement assumer des rôles de leadership à mesure que les emplois en science des données évoluent.
Bien que les compétences techniques soient toujours très demandées, avec l'IA dans l'image, nous nous dirigeons de plus en plus vers un avenir où les compétences générales, comme l'interprétation des données et la capacité à établir des relations humaines et à identifier les problèmes, seront ce qui nous séparera des travailleurs de la machine. Ironiquement, en engageant plus de machines dans notre vie quotidienne, nous pourrons peut-être renouer avec - et apprendre à valoriser - ces capacités qui nous rendent les plus humains.
A propos de l'Auteur
Écrit par Erin Vaughan
Erin Vaughan réside actuellement à Austin, au Texas. Quand elle n'est pas à l'extérieur pour profiter d'une randonnée à travers Texas hill country, elle écrit sur les dernières technologies et outils pour TrustRadius.
Écrivez pour nous
Vous pensez avoir une nouvelle perspective qui mettra nos lecteurs au défi de devenir de meilleurs spécialistes du marketing? Nous recherchons toujours des auteurs capables de fournir des articles et des articles de blog de qualité. Des milliers de vos pairs liront votre travail et vous progresserez dans le processus.