
There’s no doubt that predictive analytics has been all the rage for the last few years—and for good reason. The new algorithm-based discipline has empowered us to bring about insights that provide details on the probability of a given outcome, as well as helping us bring about the ones that are favorable.
Use cases of data science and predictive modeling comes in the form of trip-planning tools, where customers can set locations, dates, miles program memberships, hotel needs, and other factors that affect travel details. These products mark an evolution toward user-friendly data science, with tools that essentially turn the customer into the data scientist, allowing them to create their own models to return desired results.
We’ve even seen data science and predictive modeling utilized by influential companies such as Airbnb.
Back in 2014, Airbnb hosts had a problem: they never knew how to price their rentals. There were so many variables: seasonality, location and individual preferences, as well as the amenities and unique features of each property. How could hosts come up with a nightly fee that was both reflective of all those factors and likely to get them a booking?
Airbnb uses data science to solve a lot of company-wide problems; previously, they relied on data-backed insights to improve the gender diversity of their team. So when hosts needed help picking their prices, it made sense to build a selection of predictive models for them.
Enter the Aerosolve model, a dynamic pricing model designed to synthesize multiple variables to help listers pick the ideal rate for their rental. This tool is more than a mere algorithm, however. It employs machine learning technology so that data is continuously fed back into the tool. Realizing that Aerosolve had many additional potential applications, Airbnb decided to upload the code on Github for open source access.
However, what’s unique about the model is its usability. Layers are compressed into a simplified format that allows end users to understand insights—in this case, their probability of receiving a booking—as they adjust factors like the price and date.
The presentation of predictive tools in an easy-to-digest, consumer-facing user interface is exactly what the future has in store for data science.

From Predictive to Prescriptive
Those applications are also emblematic of a change sweeping through commercial data science. Data scientists are moving toward practical applications of prescriptive, rather than predictive, modeling. Whereas the latter uses historical data to predict the probability of future of events (i.e. the likelihood that it will rain tomorrow), the former assumes an active human agent capable of influencing outcomes.
Quick definitions:
- Descriptive analytics is the first stage of business analytics in which you look at historical data and performance.
- Predictive analytics is the second stage of business analytics in which past data is used with algorithms to predict a future outcome.
- Prescriptive analytics is the third stage of business analytics in which you determine the best course of action.
Data scientists might build a prescriptive uplift model to predict the likelihood of converting a lead with a certain offer, for instance, or to tell whether offering a sign-on bonus will influence a prospective employee’s probability of accepting the job.
In this way, it is much more useful for proactive planning—such as in the Airbnb use case. It also marks a blurring of the line between machine and human interactions. Older predictive models, for instance, merely offered end users insight into an event’s likelihood. It was up to human agents to decide what to do with that information.
Prescriptive uplift modeling, however, can calculate event outcomes if end users choose to pursue a certain course of action. It can, therefore, estimate whether a marketing campaign is likely to win over a certain demographic or offer solutions for a political campaign hoping to win over swing voters.
The potential applications of this kind of proactive data are practical innumerable; it’s especially useful for predicting outcomes in retail, sales, marketing, politics, and charitable donations—essentially anywhere where users hope to inspire populations towards a certain behavior.
Further Reading:
- How to Use Predictive Analytics for Better Marketing Performance
- Buyer’s Journey 101: What Your Email Data Says About Your Customers
- How to Write Content for People and Optimize It for Google
Deep Learning: Machines Take On the Processing Patterns of Their Makers
The trend toward prescriptive modeling is an interesting development, philosophically-speaking, given the growing popularity of machine-learning technologies. Modern data scientists are often called upon to work closely with software engineers in the development of new automated tools, and many of those products will employ machine learning technology.
You’ve probably already heard of this technological development—it’s a very popular buzzword in the data science field right now. However, what is less well known is precisely what machine learning is, and how it relates back to big data and data science.
Machine learning offers extraordinarily powerful applications of big data and statistical probability. It breaks down the divisions between data collection and data processing.CLICK TO TWEET
Here, machines incrementally adjust behavior and responses based on environmental data; hence, the “learning” part of the name. A real-life example of this is Amazon’s recommendation tool. The more data that users feed the tool through browsing and buying, the more precise the recommendations become.
Tools like these are evidence of real-time interactions between humans and devices. As humans respond to results, machines tailor their next offerings based on that feedback. It’s a lot more like a conversation than a chain of commands.
One particular segment of machine learning, known as deep learning, takes this evolution to the extreme. Deep learning models the structure and processing patterns of the human mind: deep learning computers are built with neural networks, with layers of nodes built on top of one another. This architecture allows nodes to make connections to one another in a nonlinear fashion, calling upon certain processing domains as necessary.
Deep learning technologies are particularly useful for mimicking the kind of visual processing performed by the brain as it responds to signals from the eyes.
For instance, the Google Translate app uses deep learning to translate unembedded text from images into another language. A user traveling in another country can snap a picture of a box of cereal or a street sign and upload it to Google Translate. Google then identifies the text on the box and returns a translation in their native language.
Similarly, another Google project, Google Sunroof, takes images from the Google Earth application and creates realistic 3D models of rooftops to use in solar installation. Using deep learning neural networks, the Sunroof tool is able to differentiate roof surfaces from trees or cars, even with the existence of obscuring factors, like shadow and tree coverage.
Deep learning tools like these allow data scientists to build predictive models based on unstructured data, such as images, video and audio, rather than merely relying on structured information like text or numbers. In this way, it opens up huge swaths of commercial data previously left untapped.
Related Content:
- 11 Digital Marketing Trends You Can No Longer Ignore in 2018
- How to Use Big Data Analytics to Grow Your Marketing ROI
- The Future of SEO: How AI and Machine Learning Will Impact Content
Data Science Converging with AI
Both machine learning and deep learning are applications of artificial intelligence (AI), and the evolving use of AI technologies like these will deeply impact the practice of data science. Again, the overarching trend is the evolution away from tools that are merely informational to ones that are transformational, as rightly pointed out by author and AI expert Carlos Perez.
AI tools take the journey from data gathering to data processing, and go one step further, by synthesizing data into designs and solutions.
For instance, Autodesk’s Project Dreamcatcher is a computer-aided design (CAD) system that uses AI to generate 3D product designs based on criteria imputted by designers, such as the functional objectives, materials required, manufacturing method, and budget.

The difference between this project and the type of tools in regular rotation today is that they don’t just allow end users to build designs. They actually provide sets of data-based solutions and help designers form prototypes designed to address specific problems.
Tools like these anticipate a future where data science moves from a strictly analytical function (synthesizing big data and offering insights and recommendations) to more product development and R&D applications.
However, some experts believe that AI technologies will eventually become so commonplace as to be ubiquitous, essentially ushering in a new industrial revolution. Machine-learning AI devices will likely affect a wide range of industries—from advertising to zoology and everything in between.
AI tools can not only do the work of the human mind, but in many cases they can do it more effectively than we ever could. Machines like these are able to mathematically prove insights that humans could only feel. Take, for instance, the company Affectiva, which uses AI equipment to recognize human emotions—anger, joy, surprise—as effectively as human leaders in commercial focus groups.
Further Reading:
- How Artificial Intelligence Is Revolutionizing the Digital Marketing Sphere
- How x.ai Came Up with the Idea for Amy the Personal AI Assistant [podcast]
- Voice Search & A.I.: Is Amazon Alexa the Start of a Robot Empire?
The End of Human-Driven Data Science?
The success of automated machine-learning tools like the ones described so far have left some in the data science field wondering if there will come a point where human experts are not necessary at all. The advanced processing potential of neural networks may very well automate the work of data scientists—in essence, according to some experts, data scientists may very well write themselves out of a job.
The question looms large in front of today’s employers. Data scientists might have been dubbed the “sexiest job of the 21st century” back in 2012, but today, the future of the role isn’t quite as clear. At a recent MIT symposium, experts mused on the field’s sustainability, with ADP VP and Chief Security Officer Roland Cloutier eventually declaring that it wasn’t wise for budding STEM students to pursue data science, since, in his words, “over time, software will do more and more of what data scientists do today.”
As Fortune points out, tools like Tableau have already made incredible strides to simplify data visualization, and there are many new programs in development to address workflows and data interpretations.
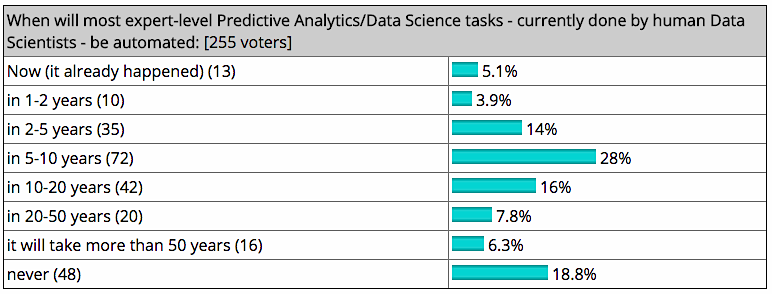
KDNuggets, an industry site for Business Analysts, Data Scientists, and Machine Learning Developers, recently polled readers for their thoughts on the matter. Only 18.8% felt that data scientists were irreplaceable by machines. Fifty-one percent, meanwhile, said they expected most tasks to be automated in less than 10 years.
Of course, not everyone has such a gloomy take on the matter. As the Harvard Business Review points out, machines are becoming much “smarter,” perhaps even more so than humans in some cases. And yet, they still largely lack the human capability to narrate their experience. Data and insights may be more complex, but devices can’t always tell us how they got there. Machines might be excellent at answering questions, but they may never be as competent as human experts at coming up with new challenges and problems to solve.
Likewise, there are times where a machine’s superhuman precision propels it across the boundaries of social mores. A famous example of this is Target, who successfully used consumer data to predict when female customers were expecting. That created the fairly awkward situation of a father learning about his teenage daughter’s pregnancy from the ads that she received in the mail. So while machines are able to make complex deductions based on patterned behavior, they’re not always able to come up with a sophisticated, tactful response—especially when the response in question falls into a moral gray area.
That argument points toward a future where data scientists behave something like “machine whisperers,” helping devices steer clear of social faux pas, and generating the missions and projects they engage in.
The Near Future of Data Science
Of course, with technology moving as fast as it does, it’s very hard to predict what any job will look like 15 years from now. In the meantime, we do know that the demand for data science is on the rise—IBM predicts a 28% increase by 2020—with most of that growth centered around finance, insurance, professional services, and IT.
For those who do work in data science, the challenge will be staying ahead of the technology. Data scientists must be constantly swimming, learning new programs and staying on top of where the field is going. However, given that many tasks may become automated in the near future, it would be wise for the businesses creating those jobs to look for candidates who can eventually take on leadership roles as data science jobs evolve.
Although hard skills will always be in high demand, with AI in the picture we are increasingly hurtling towards a future where soft skills, like data interpretation and the ability to build human relationships and identify problems, will be what separates us from machine workers. Ironically, by engaging more machines in our daily lives, we may be able to reconnect with—and learn to value—those abilities that make us most human.
About the Author
Written By Erin Vaughan
Erin Vaughan currently resides in Austin, TX. When she’s not outside enjoying a hike through the Texas hill country, she writes about the latest technology and tools for TrustRadius.
Write for us
Think you’ve got a fresh perspective that will challenge our readers to become better marketers? We’re always looking for authors who can deliver quality articles and blog posts. Thousands of your peers will read your work, and you will level up in the process.
No comments:
Post a Comment